
2025-10-20 4764 0
Enhancement of GPU-accelerated smoothed particle hydrodynamics (SPH)method with dynamic parallelism
使用动态并行技术增强GPU加速的光滑粒子流体动力学(SPH)方法

摘要: 本研究引入了一种利用CUDA动态并行(CDP)的创新GPU编程架构,旨在提高光滑粒子流体动力学(SPH)模拟的计算效率。与传统的CPU-GPU协作框架相比,动态并行能够实现动态的设备端内核启动和同步,有效缓解了由CPU-GPU通信瓶颈引起的延迟,从而提升了SPH求解器的端到端计算吞吐量。在此框架内,SPH中的邻近粒子搜索和粒子相互作用计算在GPU架构上实现了并行化。此外,动态并行通过CUDA流采用精细化的任务管理,实现了直接的设备端数据同步和并发任务调度,从而绕过了阻碍计算效率的传统CPU/GPU控制屏障。通过在NVIDIA GeForce RTX 4080 SUPER GPU上进行的两个基准测试,所提出的动态并行SPH实现方案在大规模和动态演化的粒子系统中,相较于传统的CPU-GPU SPH求解器,展示了约1.5倍至3.0倍的加速比。此外,SPH模拟与实验数据之间的均方根误差,在溃坝流中为0.03 - 0.12 m/s,在入水问题中为0.004 - 0.008 m/s。在相同的SPH算法下,采用CDP架构可以比传统的CUDA技术获得更高的计算效率。目前没有其他知名的SPH软件使用此CDP概念,这应该是CDP首次在基于GPU的SPH模拟中得到应用。 引言: 为了在无网格的光滑粒子流体动力学(SPH)模拟中解析精细的表面特征并实现高保真精度,所需的粒子数量必须呈指数级增长。具有高空间分辨率的、物理精确的大规模实时流体动画通常需要百万级别的粒子系统,这对计算资源提出了严格的限制,并需要高性能计算(HPC)技术。 自其首次应用于计算流体动力学(CFD)以来,SPH建模技术已被广泛应用于各种工程领域。GPU计算技术的快速发展使GPU加速的SPH算法成为计算力学中的一个关键研究课题。当Kipfer等人和Kolb等人分别提出了用于宏观流体模拟的GPU兼容解耦粒子系统时,基础性工作开始涌现。随后,Kolb和Cuntz介绍了一种GPU原生实现的动态粒子耦合方案。接着,Harada等人提出了一种基于GPU的SPH邻近粒子搜索算法,这标志着首个GPU原生的SPH实现。在计算统一设备架构框架提出之前,上述方法在实现GPU线程的高效空间调度和系统化利用内存资源方面遇到了严重限制,因此其计算效率远低于理论预期。英伟达在2007年创新性地推出了CUDA技术,并于2008年将其应用于粒子模拟,随后在Green中得到了进一步完善。Hérault等人提出了最早的基于CUDA的SPH方法实现,与此同时,Goswami等人提出了一种利用CUDA共享内存优化SPH的方法。Dominguez等人为SPH的CPU/GPU实现提出了若干改进的优化策略,两年后,Crespo等人提出了开创性的开源代码Dual-SPHysics,用于在CUDA架构上执行SPH计算。Xia和Liang在浅水流动计算中提出了使用四叉树而非格子链表的邻近粒子搜索方法。然而,由于缺乏动态并行性,他们的算法未能充分利用GPU的并行化优势。另一个开源SPH求解器gpuSPHASE尝试优化共享内存的使用而非全局内存。然而,他们的系统仅加载了主粒子,因此性能提升并未完全实现。此外,Huang等人开发了一个更通用的GPGPU加速框架,主要用于SPH中的邻近粒子搜索,并充分利用了GPU缓存(例如共享内存和寄存器内存)。近年来,基于GPU的SPH领域也取得了重大进展。例如,Yang等人将带有自适应粒子细化的GPU实现到SPH框架中,以研究多相流和流固耦合应用。Zhang等人提出了一种基于GPU的大规模SPH模拟,采用自适应空间排序技术,用于汽车行业中常见的车辆涉水问题。此外,Cen等人在单GPU上开发了一种加速的单相表面张力SPH求解器,用于在3D实际尺度模拟数百万个粒子。 总的来说,除了算法方面,多年来SPH中GPU实现的性能障碍仍然是内存使用、负载平衡以及中央处理器(CPU)和GPU之间的高延迟通信。解决此瓶颈的最终方案可能是通过所谓的动态并行性来实现。CUDA动态并行(CDP)作为一种架构创新,显著增强了GPU的计算能力,并在近年涉及复杂任务和大规模问题的应用中展示了巨大潜力。CDP原理由Jones等人首次提出,其核心在于允许各种GPU线程动态启动子线程,从而实现更灵活和并行化的设计。最初的研究专注于CDP在聚类算法和非结构化GPU应用中的性能。随后,Zhang等人将CDP引入图优化,而Neelima等人研究了其在递归排序方面的有效性。Plauth等人[24]评估了CDP在处理细粒度不规则工作负载时的性能,并表明CDP理论上可以提高计算性能。 另一方面,为了解决CDP在内核启动频率和线程分支效率方面的性能问题,各种研究人员提出了一系列优化方案。例如,El Hajj等人开发了内核启动聚合与提升(KLAP)技术,显著减少了内核启动开销,从而提高了吞吐量。Tang等人通过控制内核启动进一步优化了CDP的调度效率,Jarzabek和Czarnul则将CUDA统一内存(UM)技术应用于更复杂的递归算法。最近,Bozorgmehr等人通过动态并行化一个3D红-黑超松弛(SOR)风场求解器,实现了128倍的性能提升。Wu将CDP应用于Barnes-Hut算法的大规模N体模拟,Kento等人提出了一种基于CUDA图的自适应内核执行方法,提高了动态应用的资源利用率。与持续改进模拟和检测任务计算效率的努力相一致,计算机视觉和深度学习领域的最新研究——例如Sarhadi等人[31]使用SWIN U-Net架构进行优化的混凝土裂缝检测——凸显了注意力机制和架构级增强在实现高性能结果中的作用。 本研究探讨了在SPH模拟中实现CDP2(CUDA动态并行2),以在GPU加速计算效率方面实现突破性进展。利用CDP2的架构特性,本研究旨在为SPH粒子系统开发两种创新范式。与为每个粒子计算分配单线程执行的传统CUDA实现相比,所提出的CDP2支持多线程协作。此外,当前工作还提出了一种内核内流框架,用于协调动态生成的子内核的数据同步和计算调度,从而在SPH并行计算中实现不依赖CPU的控制逻辑,进而消除CPU-GPU同步延迟。而且,CDP2架构能够通过需求驱动的线程块配置来固有地优化GPU工作负载平衡。这仅需要在块内进行局部资源分配,因此显示出与迭代操作增强的兼容性。 全文结构如下。第2节描述了SPH方法的基础知识和传统的CUDA GPU实现。第3节专门介绍CDP2与SPH求解器的创新并行化策略。第4节介绍了两个选定的基准案例,用于评估计算加速效果。最后,第5节总结了结果并提出了未来的研究发展方向。 图表: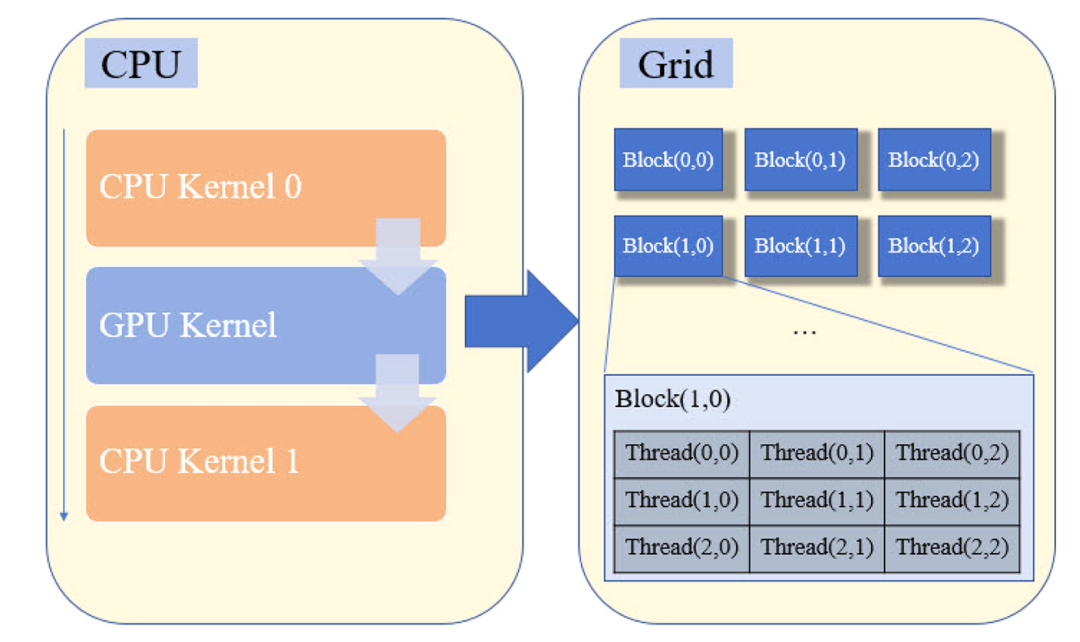
图1 CUDA程序框架示意图
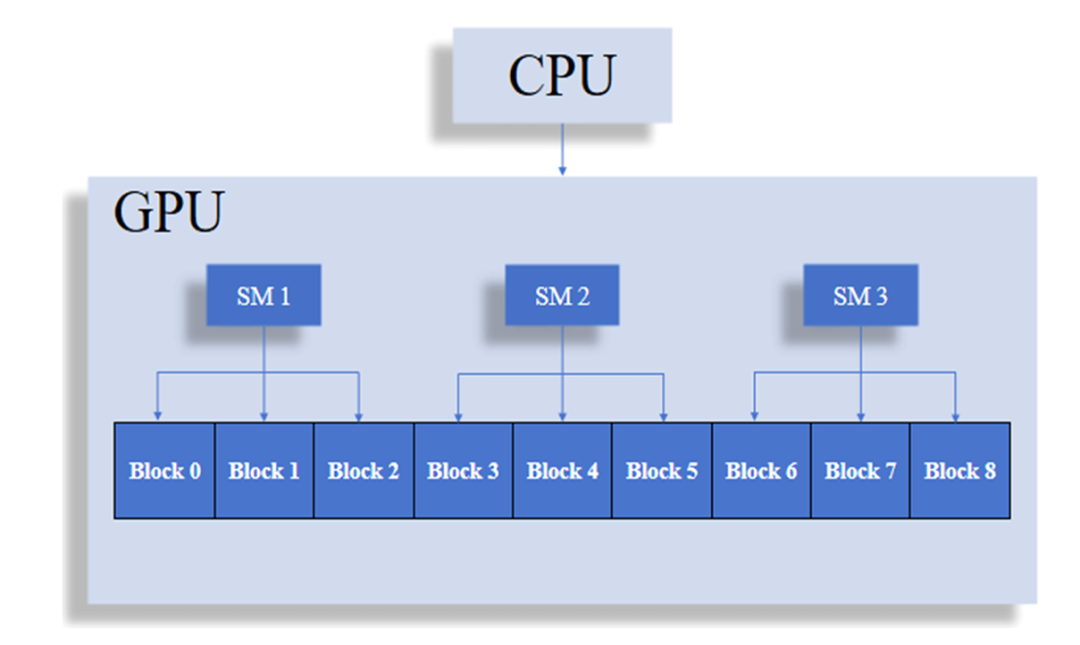
图2 GPU调度机制示意图
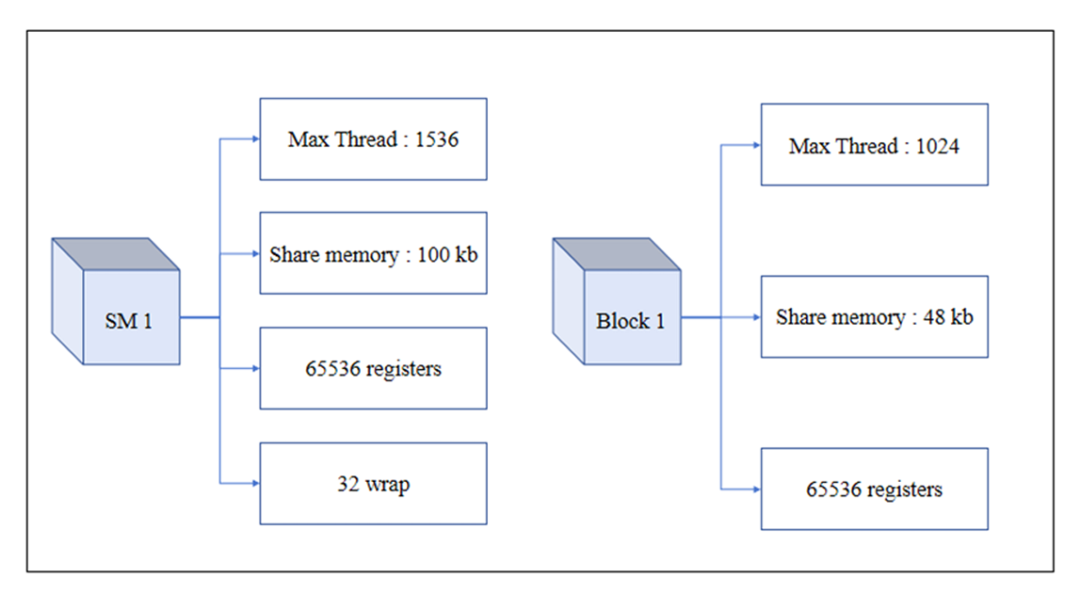
图3 NVIDIA GeForce RTX 4080 SUPER 内存配置模型
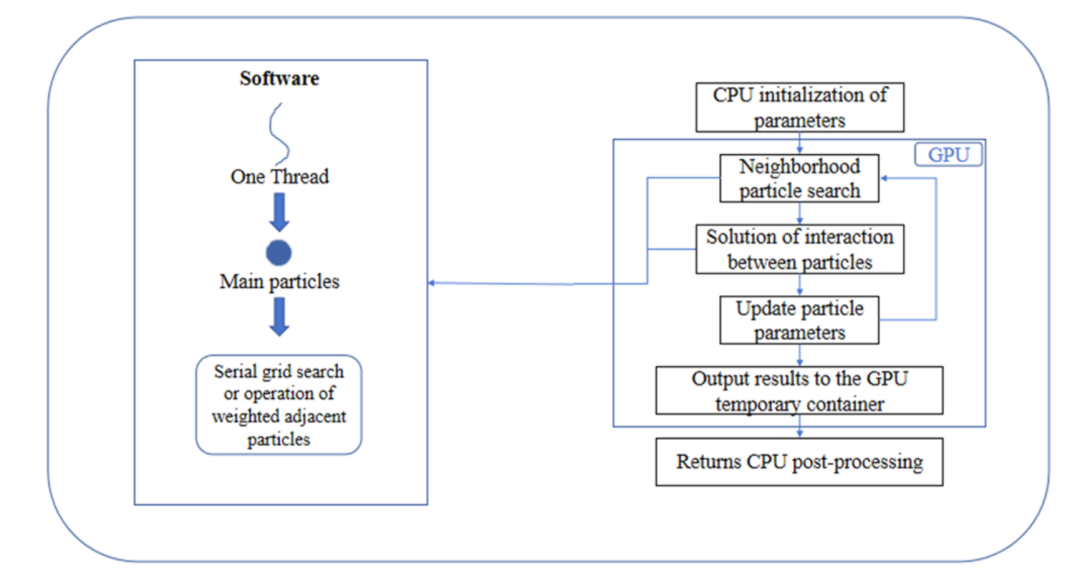
图4 传统CUDA实现的GPU-SPH中的线程利用率
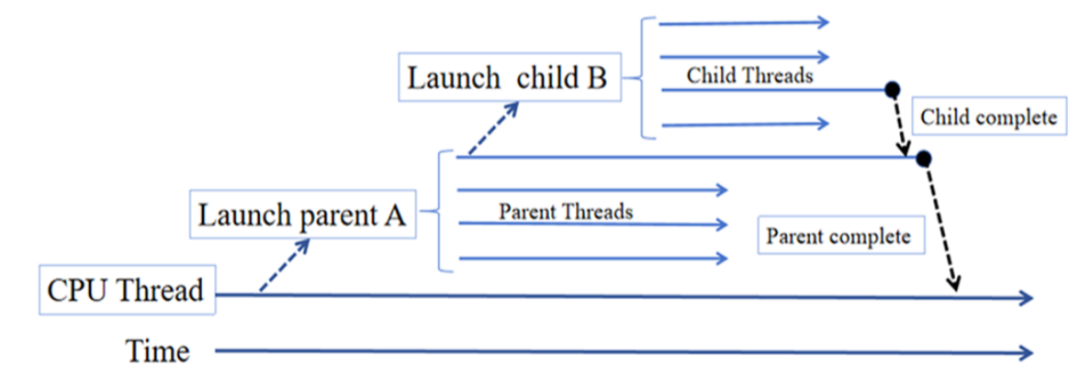
图5 CUDA动态并行中的父子内核启动嵌套关系
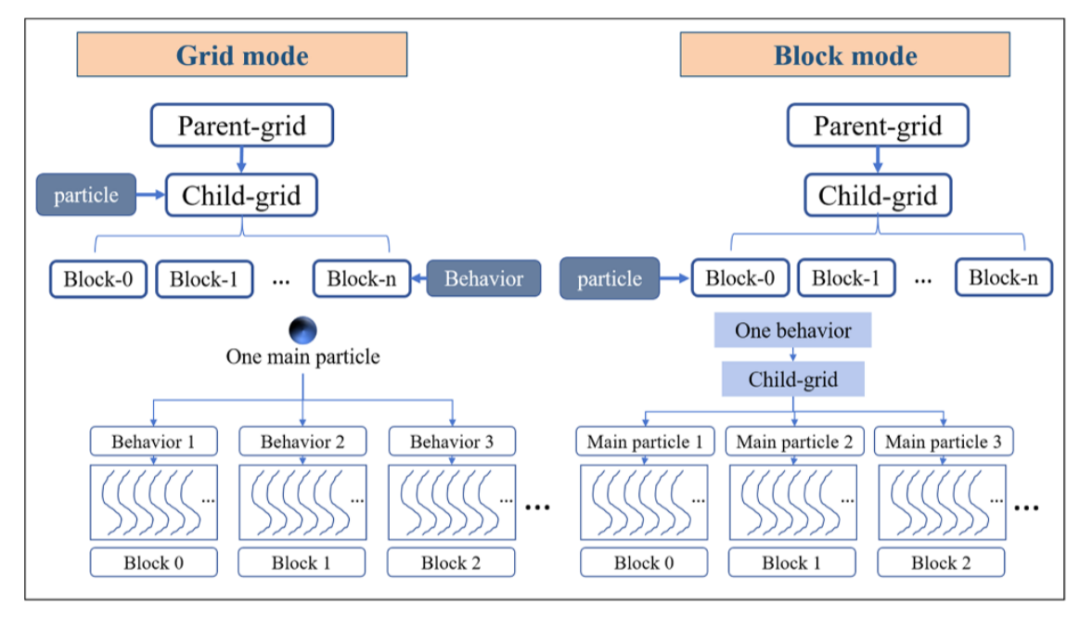
图6 CDP2-SPH子内核计算中的块模式与网格模式
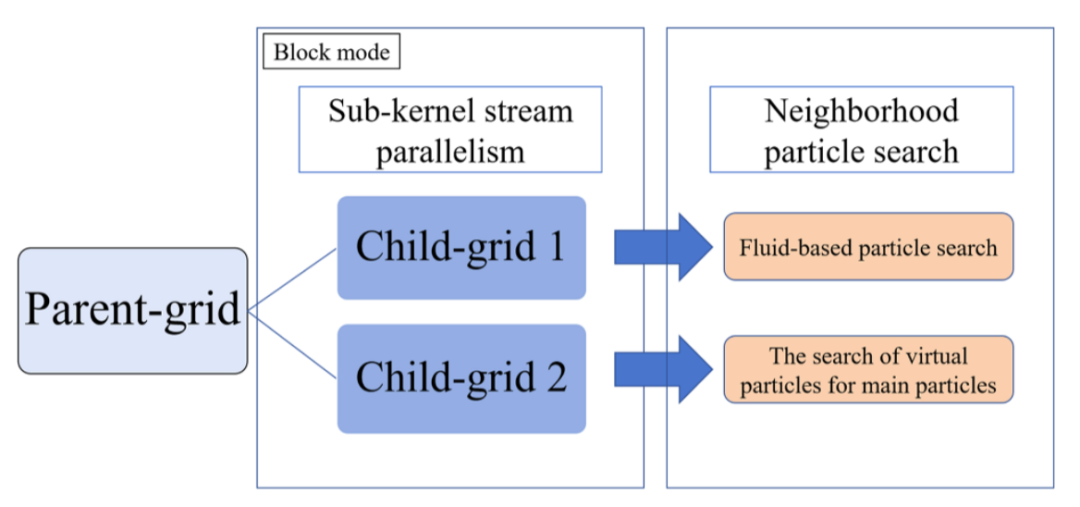
图7 CDP2-SPH框架中的邻近粒子搜索
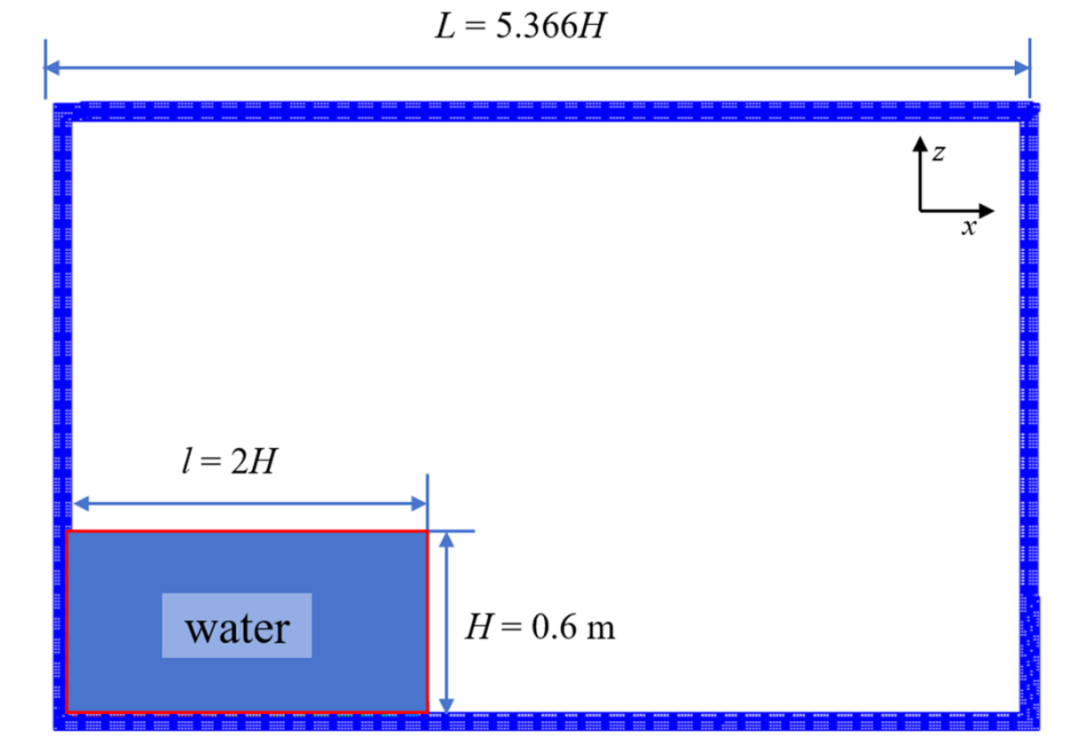
图8 二维溃坝流配置的数值设置
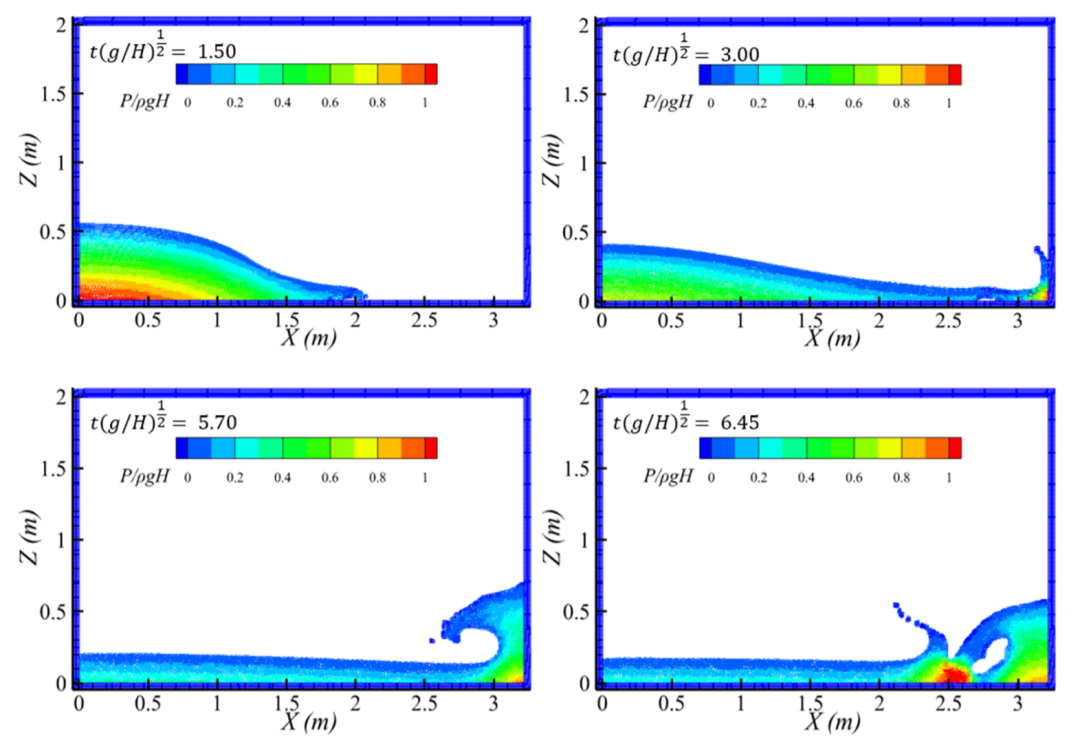
图9 CDP2-SPH计算得到的多个时刻溃坝流粒子分布图
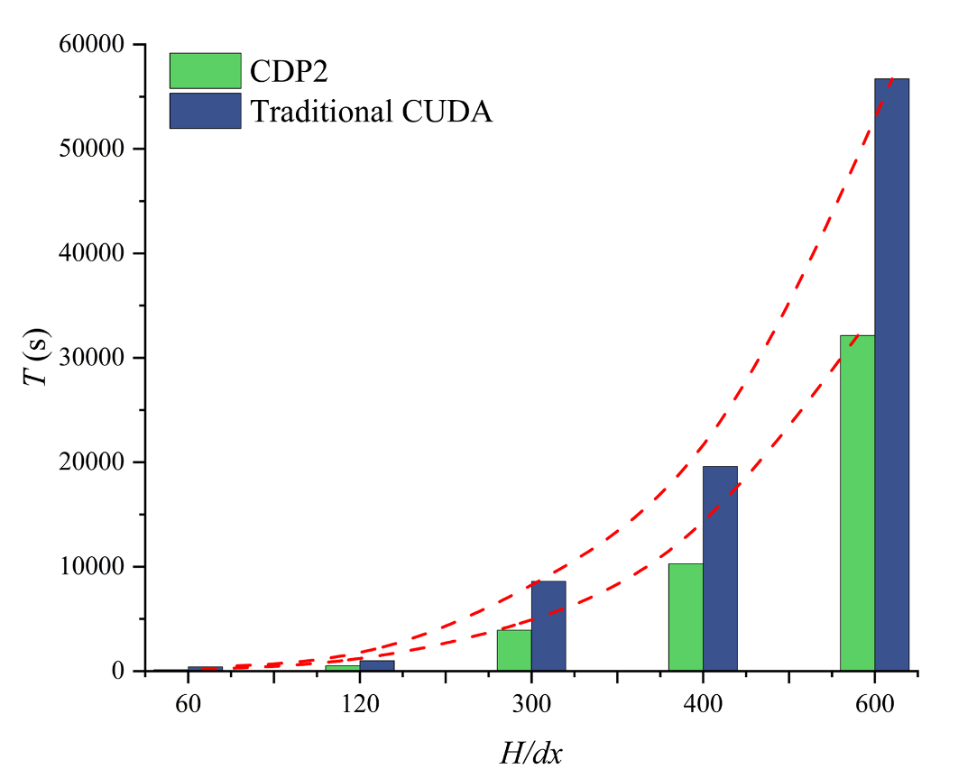
图10 CDP2与CUDA在二维溃坝流中的计算时间对比
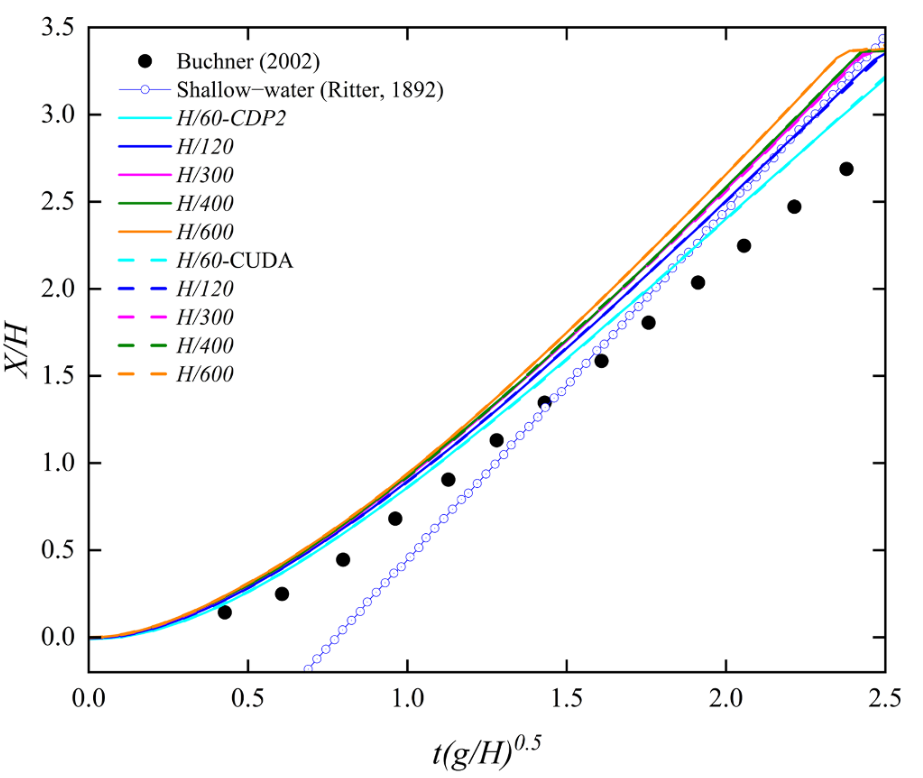
图11 SPH模拟与实验数据中随时间变化的前缘位置对比

图12 三维溃坝流配置的数值设置
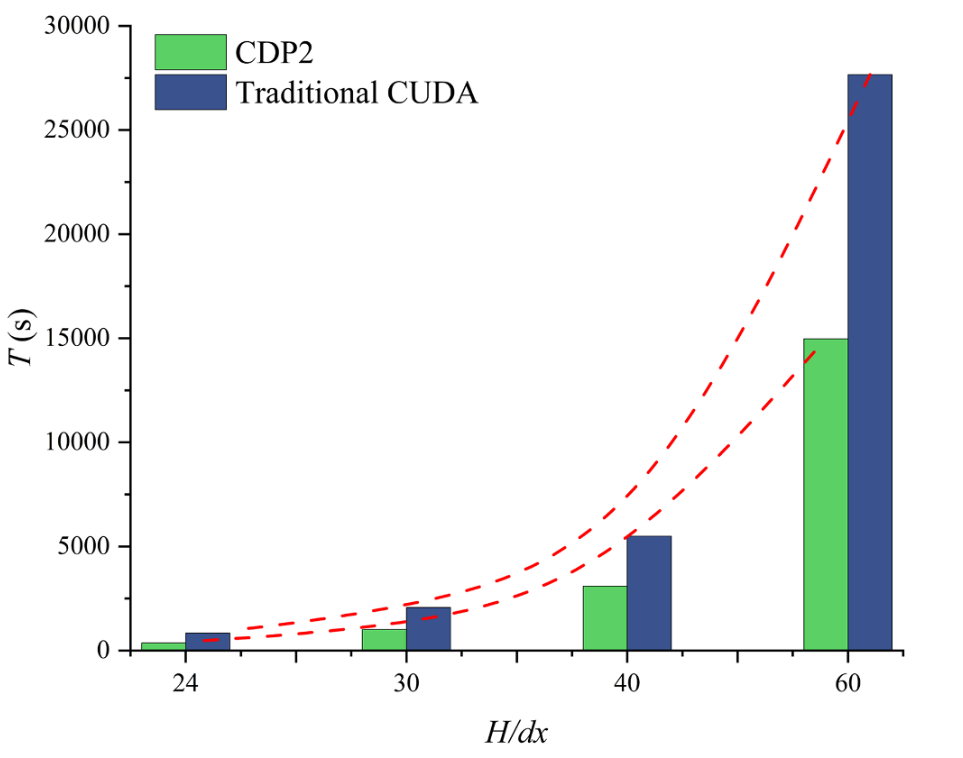
图13 CDP2与CUDA在三维溃坝流中的计算时间对比
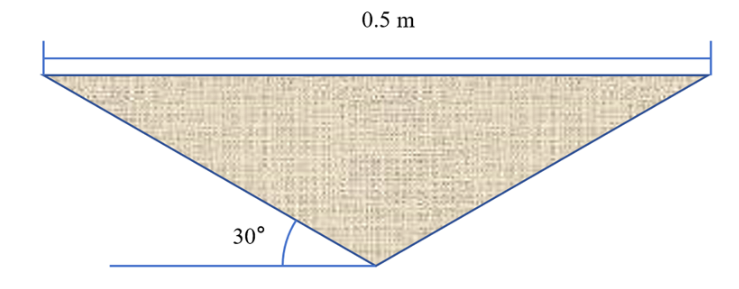
图14 实验中使用的楔形模型几何形状
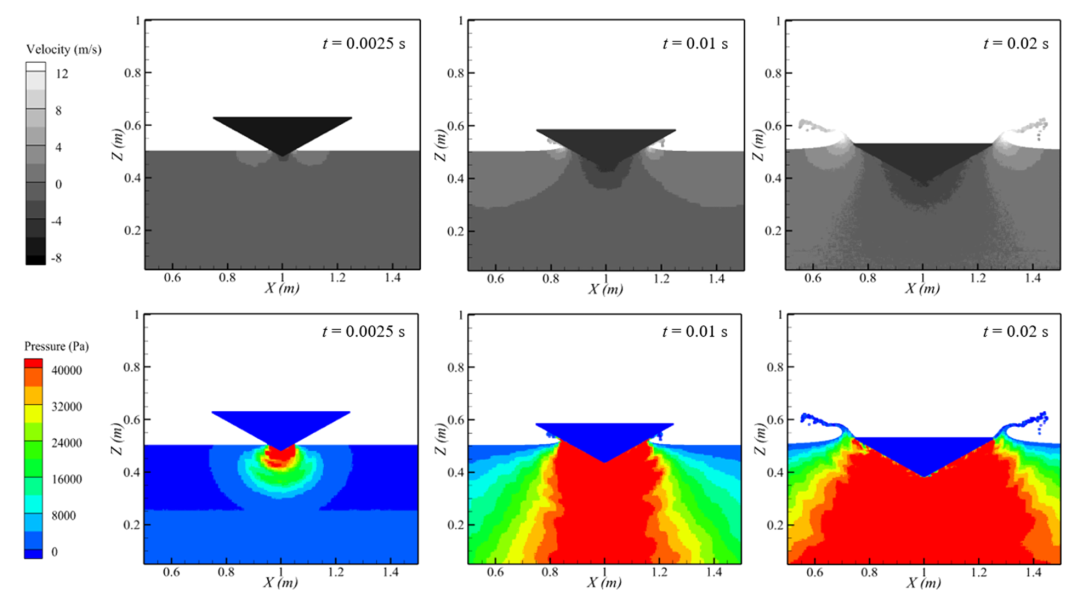
图15 CDP2-SPH计算得到的楔体入水过程中的速度场与压力场
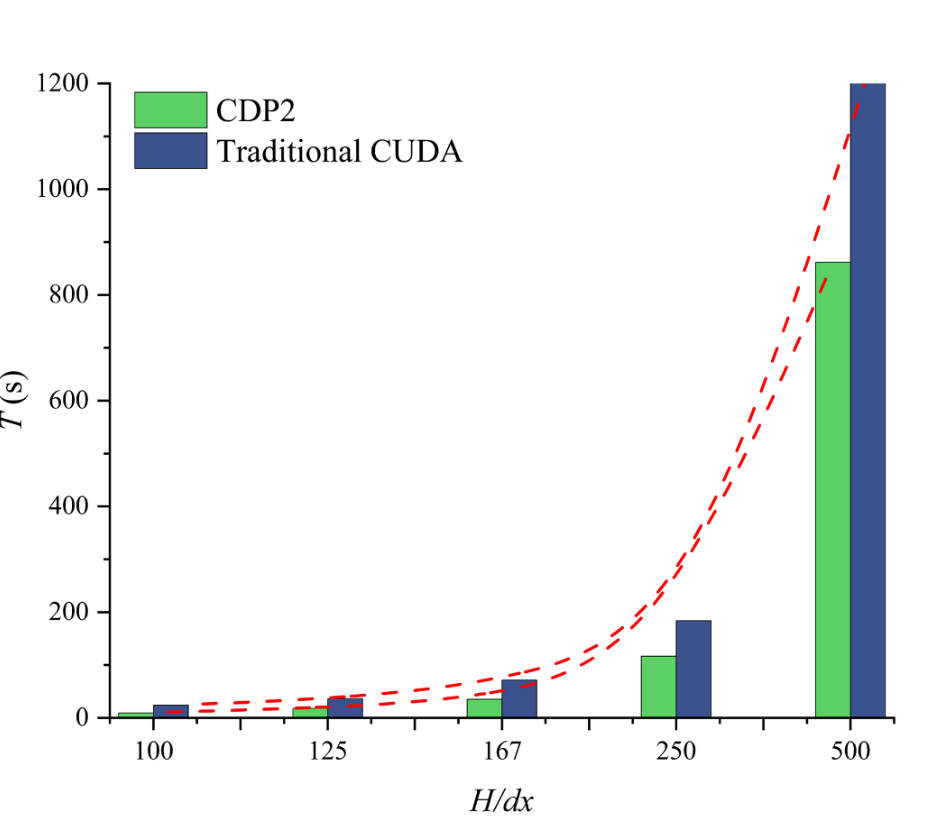
图16 CDP2与CUDA在二维楔体入水问题中的计算时间对比
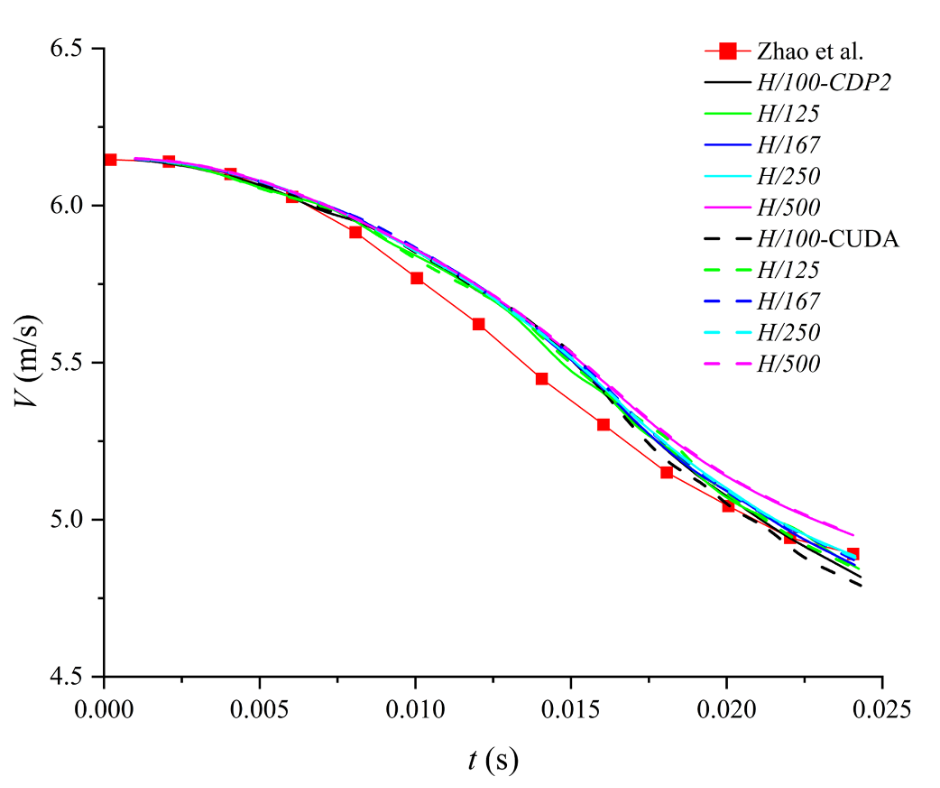
图17 SPH模拟与实验数据中随时间变化的速度剖面对比
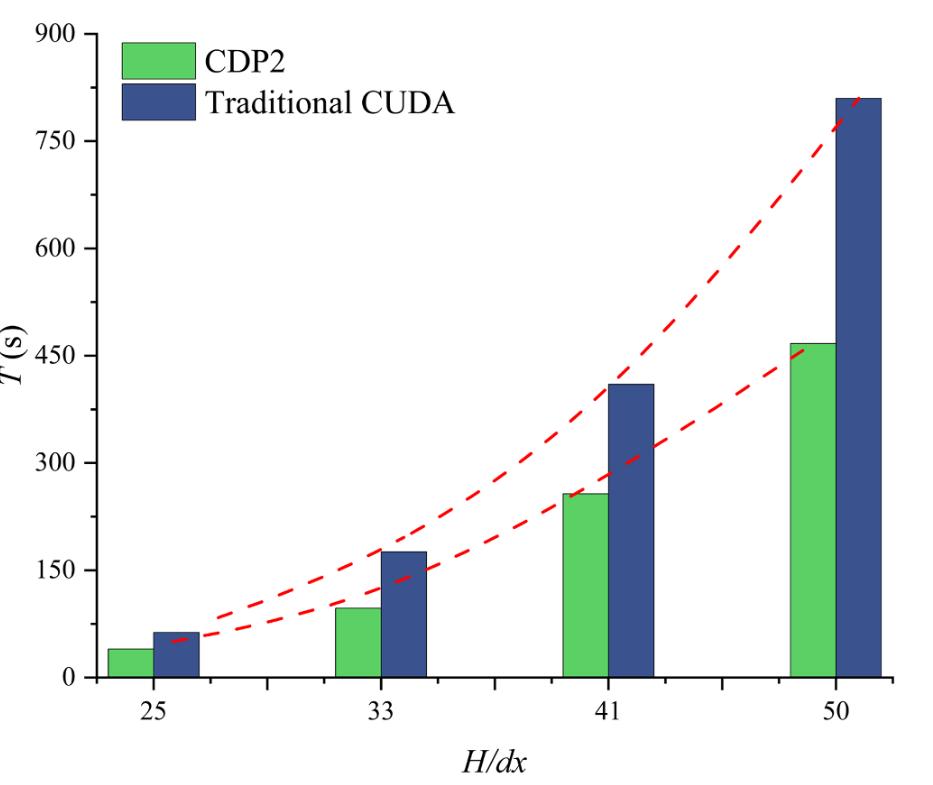
图18 CDP2与CUDA在三维楔体入水问题中的计算时间对比
结论: 本研究提出了一种CDP2加速的GPU-SPH计算框架,通过两种面向SPH的编程技术——块级和网格级配置,提升了传统CUDA的任务并行性。块级优化架构通过利用CUDA流实现子内核间的并行化来改进SPH模型,而网格级优化则为粒子提供多线程块平台,并在需要时提供额外的线程。我们仅在块模式下通过利用流优化各种子内核之间的内核函数并行化来增强SPH代码。网格模式仅作为概念框架提出,因为它需要不同的子内核来计算粒子。对于涉及大量粒子的场景,不推荐使用此模式,其潜力应进一步探索。需要指出的是,在相同的SPH算法下,采用CDP架构可以比传统CUDA技术获得更高的计算效率。目前没有其他知名的SPH软件使用此CDP概念,这应该是CDP首次在基于GPU的SPH模拟中得到应用。 通过在NVIDIA GeForce RTX 4080 SUPER GPU上进行的两个基准测试,提出的CDP SPH实现相较于CUDA的加速比为:在2D溃坝流中达到1.76倍-2.88倍,在3D溃坝流中达到1.78倍-2.32倍;而在楔体入水问题中,2D和3D的加速比分别为1.42倍-2.58倍和1.60倍-1.81倍。此外,SPH模拟与实验数据之间的均方根误差,在2D配置中,溃坝流为0.03-0.12 m/s,楔体入水为0.004-0.008 m/s。值得注意的是,CDP的加速优势在3D楔体入水场景中明显下降。这并非CDP基本架构的缺陷,而是与刚体跟踪方案中未解决的多线程原子求和冲突有关,该问题在CDP2和CUDA实现中都会导致不可避免的延迟管道。 为了在3D SPH流固耦合中充分发挥CDP的潜力,应针对双向流固耦合过程开发进一步优化的GPU闭环架构。CDP2相对于CUDA的加速比随着粒子数量的增加而下降。这一趋势源于CDP架构的基本机制:CDP的加速原理之一是通过并行化邻近粒子的串行加权计算,更有效地利用GPU硬件资源,从而增强基于CUDA的SPH计算的并行性。这意味着在相同粒子数和相同时间范围内,CDP可以利用更多GPU资源并实现高负载操作。然而,随着粒子数量的增加,GPU资源变得饱和,因此CDP的优势相应减弱。但应注意,CDP也具有负载平衡功能,因此在这方面仍比CUDA更具优势。另一方面,对于大规模粒子计算,与传统CUDA架构相比,CDP在更高粒子数下仍能保持较高的加速比。也就是说,尽管加速优势随着粒子数量的增加而下降,但这实际上是指所有CDP计算本身。与CUDA计算相比,CDP在整个数据分辨率范围内始终更高效。 然而,也应认识到CDP2方案也引入了额外的性能开销,例如与控制逻辑、数据同步和资源分配相关的开销。此外,尽管本研究侧重于CDP2与SPH的耦合,但相关方法和技术也可以扩展到高效并行处理占主导地位的其他科学计算领域。 参考文献:
[1]Xue L, Gu S, Shao S. Enhancement of GPU-Accelerated Smoothed Particle Hydrodynamics (SPH) Method with Dynamic Parallelism[J]. Results in Engineering, 2025: 106799.
版权声明:
本文仅用于学术交流与分享,版权属于原作者/出版商。文字翻译部分仅代表小编个人理解,如果错漏或侵权,请联系小编修改或删除。
 成功提示
成功提示
 错误提示
错误提示
 警告提示
警告提示








评论 (0)